CS - SDK#
csSDK (ConverSight Software Development Kit) is an optimized and updated version of ConverSight Library. Functionalities are same as ConverSight Library. But it is a combination of low code and no code environment. It is enhanced in such a way to optimize the time taken for every action.
Using the csSDK, a range of actions can be executed including connecting datasets, viewing dataset details and metadata, retrieving group and role information, running queries and accessing pinned Storyboards. In the future, the csSDK will enable the creation, updating and deletion of Proactive Insights, Relationships, Drilldowns, smart analytics, smart column and smart query through Notebook.
The csSDK Library has two powerful functionalities that serve as its backbone:
Dataset Functionalities
Pinboard Functionalities
Dataset Functionalities#
Let’s take a closer look at Dataset Functionalities, which enable users to work with datasets. To start with csSDK Library in Jupyter Notebook, first import dataset from csSDK Library.
from csSDK import Dataset
# This will import all the dataset from the csSDK Library
When you use ConverSight Library without entering a dataset ID, it connects to all the datasets in the library. However, about the CS-SDK, this will necessitate a specific dataset ID.
ds = Dataset("6412ae74-N3VuSsa4m")
#where "6412ae74-N3VuSsa4m" is the dataset ID

Dataset Load#
NOTE
The keyboard shortcut Shift + Enter is utilized to execute a cell.
Available Methods in Dataset#
Pressing the Tab button on an object or function displays a list of the available functions. List of available methods for dataset are shown in the below screenshot.
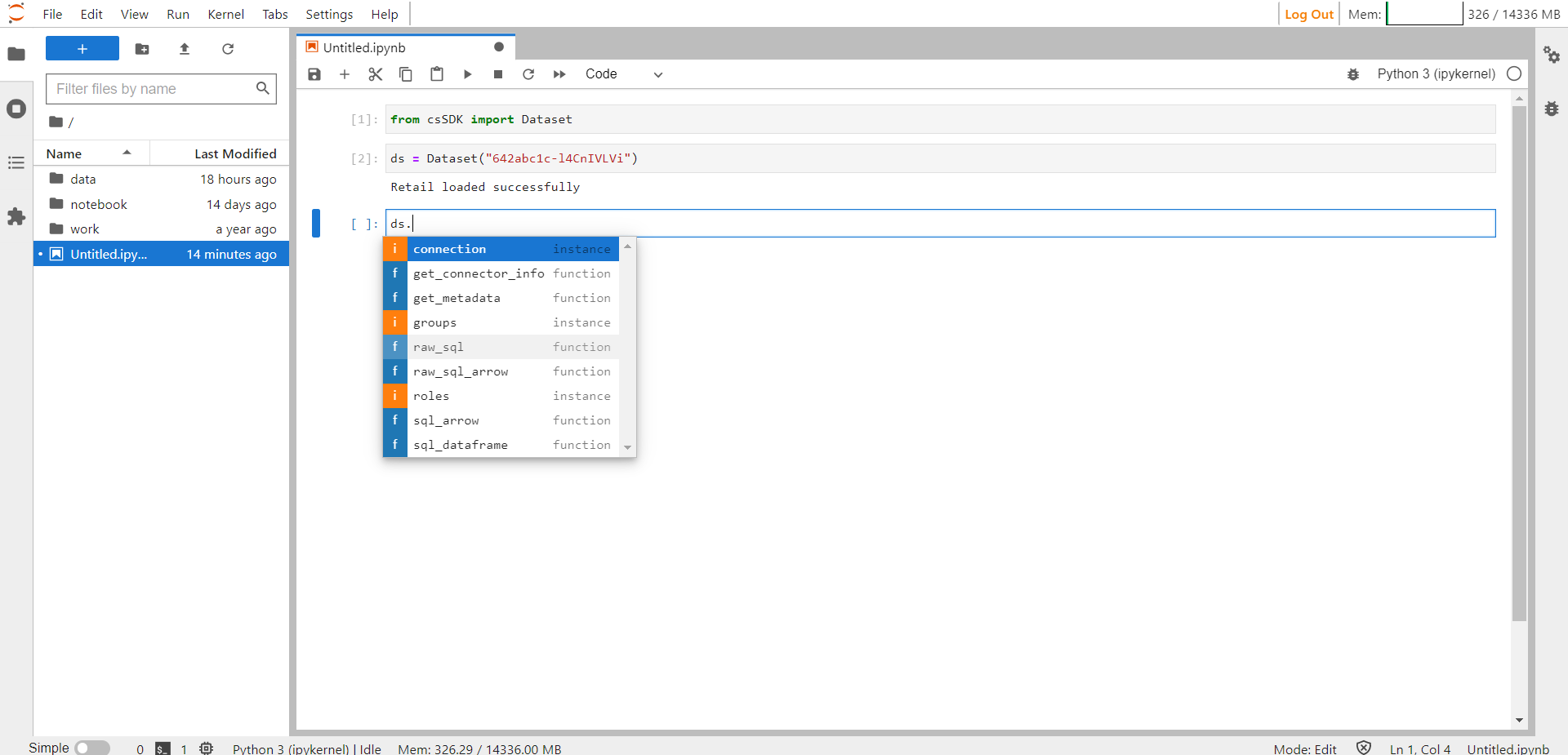
Available Functions in CS SDK#
NOTE
The keyboard shortcut Shift + Tab is used to view the help guide for a method.
Connection#
The purpose of a connection is to establish a link to datasets, enabling users to access information about tables and execute queries. There are several methods that can be found in a connection, such as:
execute
get_tables
get_table_details
load_table

Available Functions in Connection#
Execute: The execute() method is utilized to run a query on tables and provide the results to users. It can take either SQL query or object as arguments but any one is mandatory
Sql_ds=ds.connection.execute("""SELECT
round(
sum(coalesce(m_642abc55_RetailSales."m_revenue", 0)),
4
) AS "label_RetailSales.revenue",
m_642abc55_RetailSales."m_buyer" AS "label_RetailSales.buyer",
round(
sum(coalesce(m_642abc55_RetailSales."m_units", 0)),
4
) AS "label_RetailSales.units"
FROM
m_642abc55_RetailSales
GROUP BY
m_642abc55_RetailSales."m_buyer",
m_642abc55_RetailSales."m_buyer"
ORDER BY
m_642abc55_RetailSales."m_buyer",
m_642abc55_RetailSales."m_buyer"
LIMIT
50002""")
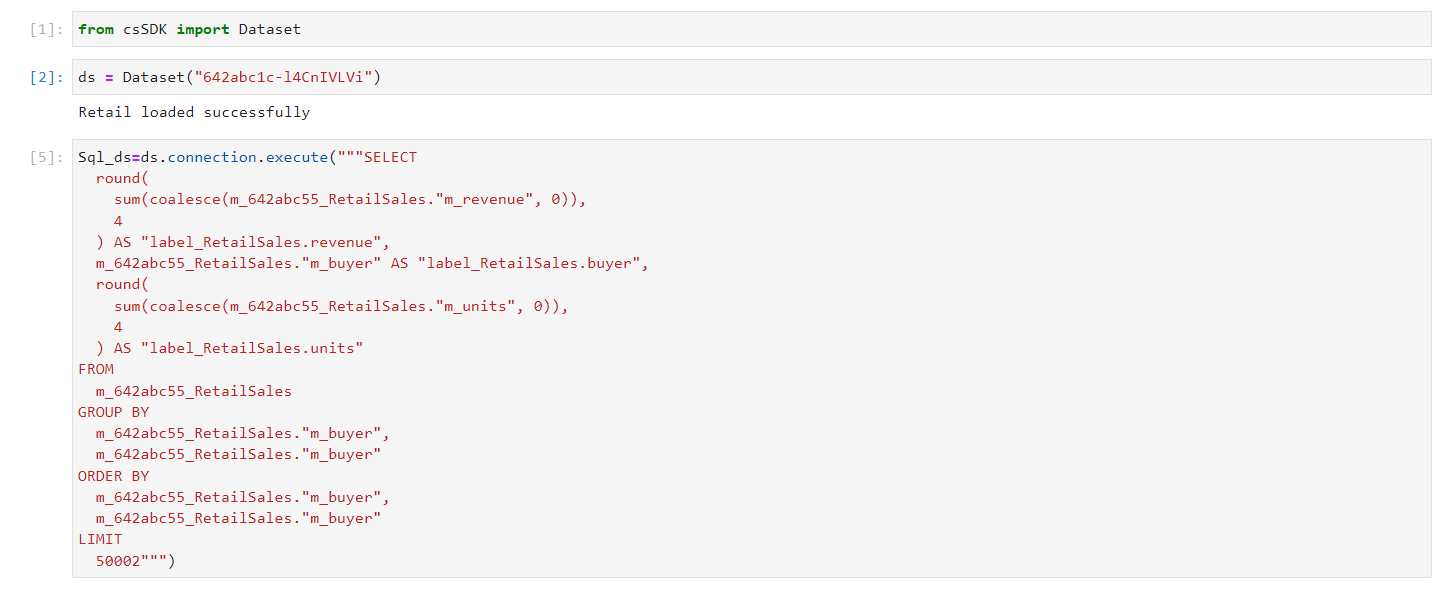
Executing a SQL Query#
Get Tables: The get_tables() method enables users to obtain a list of all the tables that exist within a database, including their corresponding table ID. This information can be useful for users to gain insight into the available tables.
tables=ds.connection.get_tables()

List of Available Table in the Dataset#
Get Table Details: The user can use get_table_details() method obtain information regarding the column and data types of the given table. It is essential to have the table name to access the details, as an error would be generated otherwise.
The user can refer to the help guide to determine the necessary arguments required for utilizing the method.
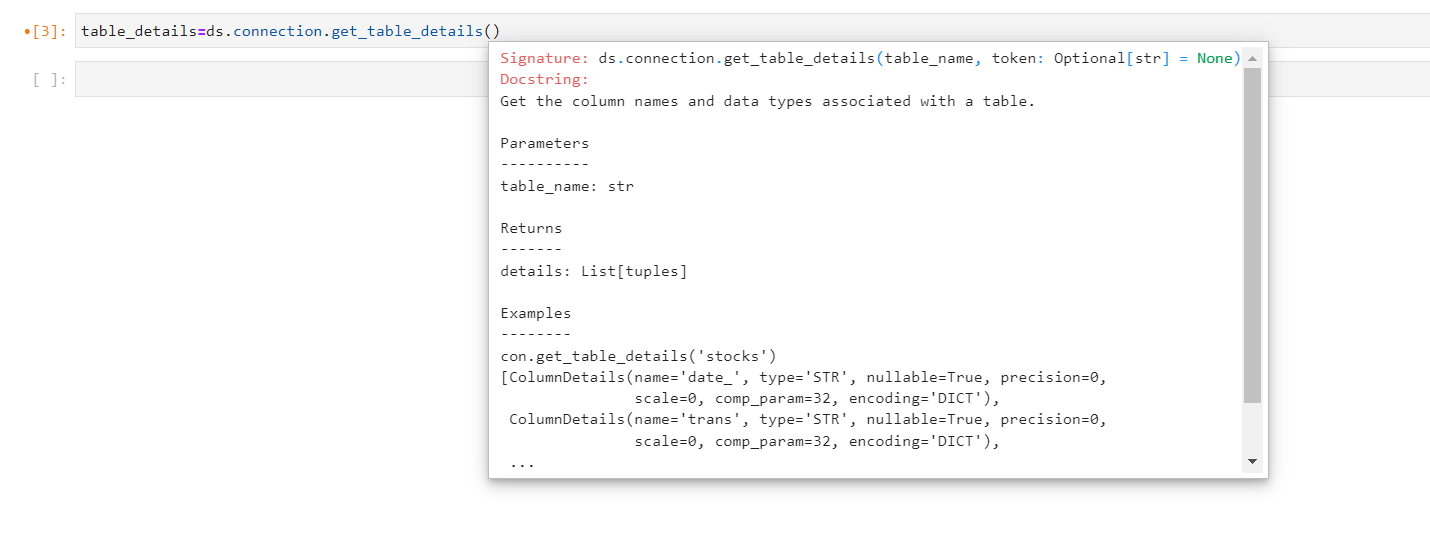
Get Table Details Help Guide#

Get Table Details Method#
Load Table: The load_table() method allows the user to load a table into a database. If the table already exists and its size matches, the data in the table will be appended. However, if the size does not match, an error will be thrown. On the other hand, if the table name does not exist, a new table will be created with that name and the data will be loaded into it.
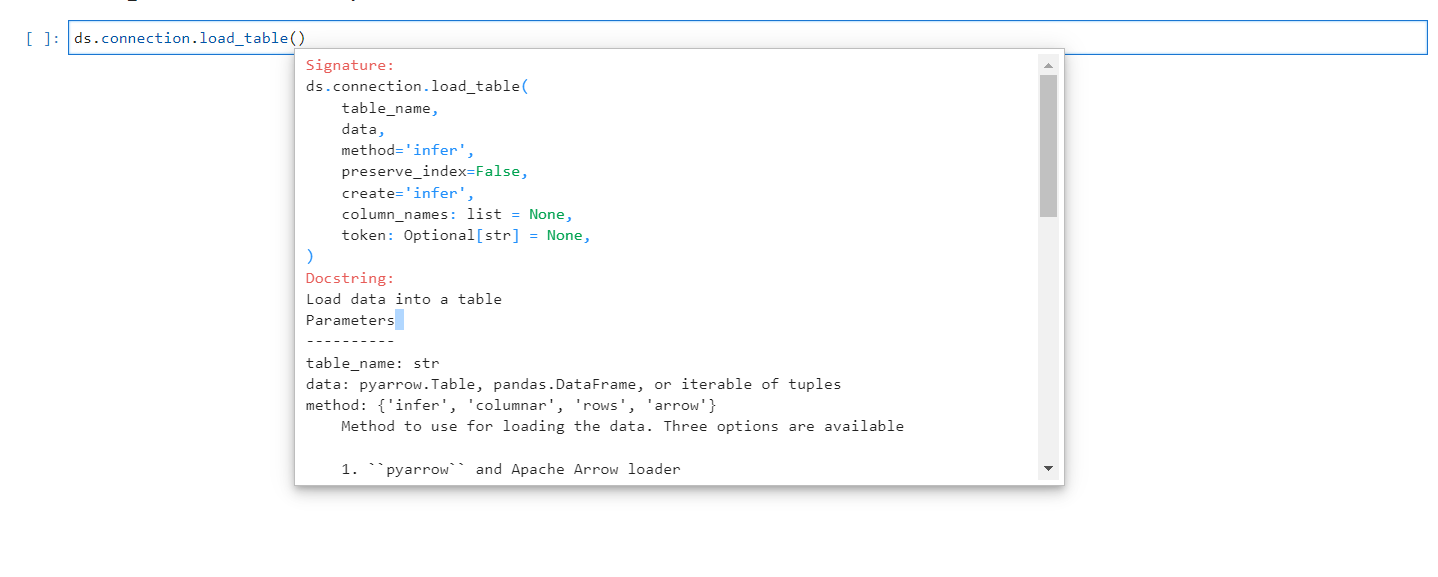
Load Tables Arguments#
ds.connection.load_table(table_name="Retail", data=df)

Load Table#
Get Connector Information#
The get_connector_info() method involves in extracting information of the connector and presenting it to the user in a comprehensible format, which includes information such as the name of the database, the schema, the tables, the URL and the username. It is noteworthy that in many cases, the password is obscured as a security measure, appearing as a series of asterisks (*****).
con=ds.get_connector_info()
The available methods in get_connector_info() are:
database
password
schema
tables
url
username
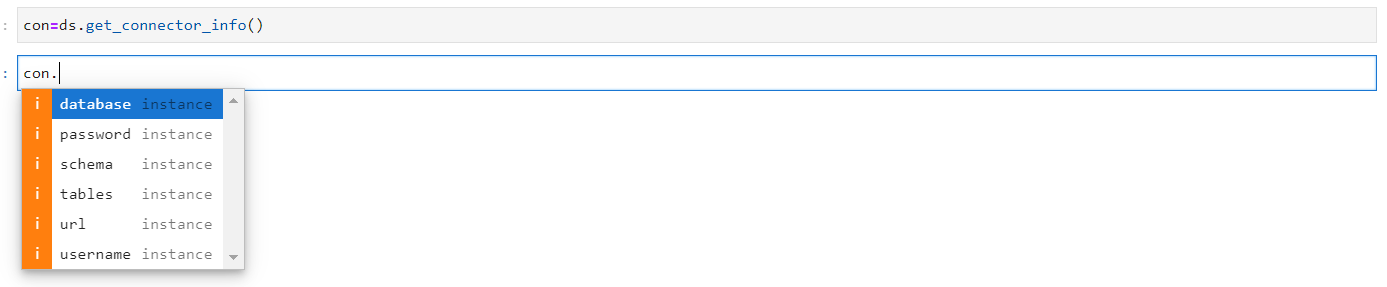
Get Connector Information Methods#
Database: The database retrieves the name of the database that is currently connected.

Database Method#
Password: For security purposes, the password retrieves a series of asterisks representing the password that has been given to the database.

Password Method#
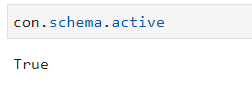
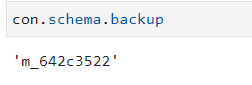
Schema: The schema provides information about the connector’s schema. The avaialble methods under schema are:
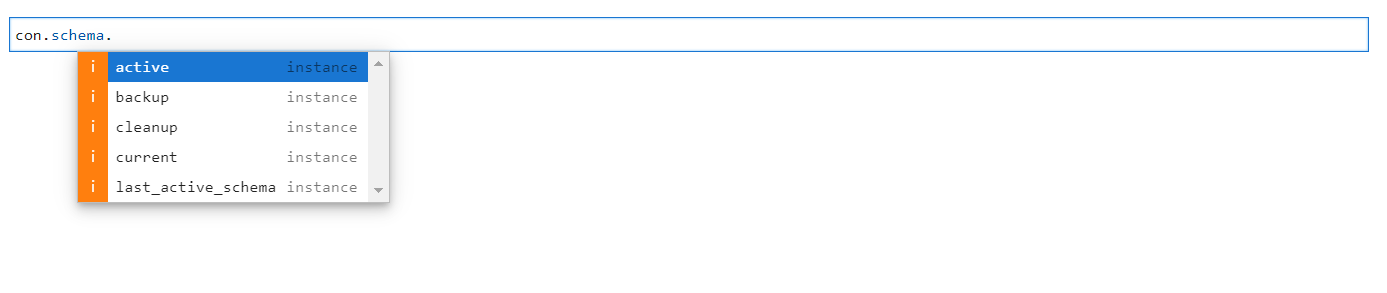
Schema Methods#
Method |
Description |
|---|---|
active |
The active method indicates whether a schema is currently active or inactive. |
backup |
The backup method shows the ID of the backup schema. |
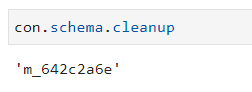
cleanup |
The cleanup method shows the ID of the deleted schema. |
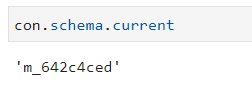
current |
The current method shows the ID of the currently running schema. |
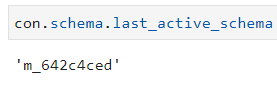
last_active_schema |
The last active schema shows the ID of the last active schema. |
Tables: The table method shows the list of tables that are available in the dataset.

Table Method#
URL: The url method shows the URL utilized for establishing a connection to the dataset

URL Method#
Username: The username displays the user associated with the dataset.

Username Method#
Get Metadata#
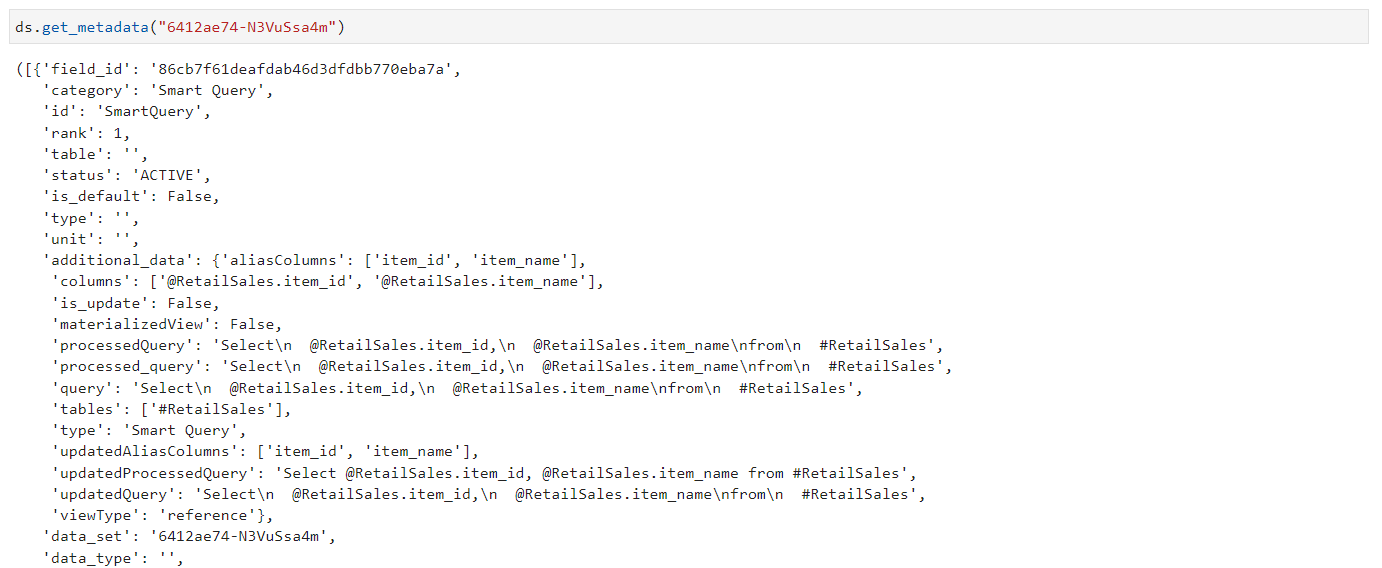
The get_metadata() method retrieves comprehensive information about a dataset, including all properties of every table and column. This method can be useful for data analysts and developers who need to understand the structure and content of a dataset in detail. Dataset ID is mandatory for this method
ds.get_metadata("6412ae74-N3VuSsa4m")
# where "6412ae74-N3VuSsa4m" is the Dataset ID
Metadata Method#
Groups#
The group method contains only the get method, which displays the group ID, group name, description, dataset, column list, settings and form list. The user can use this method to understand about the permission and access given to the database.
ds.groups.get()

Groups#
Roles#
The roles method retrieves information about the roles associated with a dataset, including the role ID, name, description, dataset and role filter. This method is useful for understanding the permissions and access of the roles. By using the roles method and the get function, developers and data analysts can quickly retrieve important information about the roles defined within a dataset.
ds.roles.get()

Roles#
Raw SQL#
Raw SQL is a fundamental and low-level approach to interacting with databases. The raw_sql() method is used to process the SQL queries and display the results in a tabular format. This method is useful for advanced users who need more granular control over their database interactions and who are comfortable working directly with SQL queries. The raw_sql() method may become a more integral component of larger database interaction workflows.
ds.raw_sql("""SELECT round(coalesce(sum(m_6315f1de_RetailSales."m_revenue"), 0), 4)
AS "label_RetailSales.revenue",
datepart('year',
m_6315f1de_RetailSales.
"m_sales_date_1")
AS label_year FROM
m_6315f1de_RetailSales
GROUP BY label_year ORDER BY
label_year LIMIT 50002""")
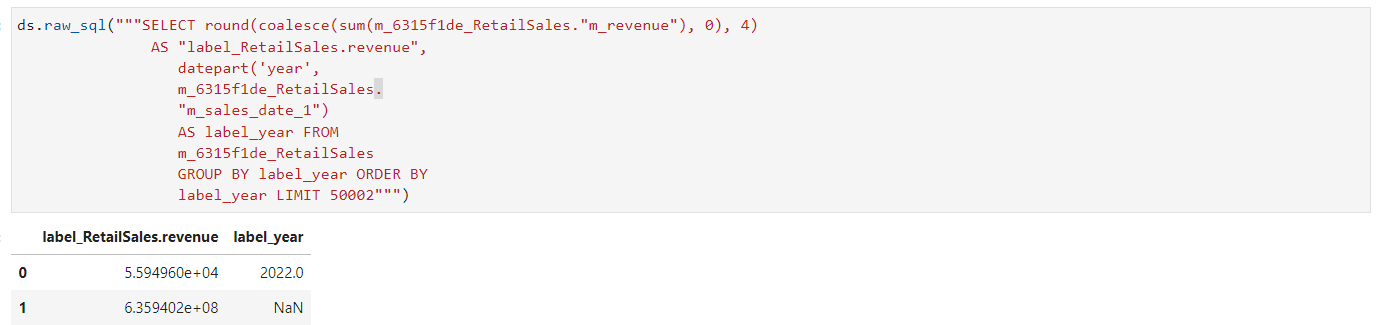
Raw SQL Method#
Raw SQL Arrow#
Arrow SQL can be used alongside normal SQL to improve the performance and efficiency of data processing tasks. Arrow SQL can be used to transfer data between different systems without the need for expensive data conversions, which can save time and resources. Additionally, Arrow SQL can be used to optimize queries by leveraging the highly efficient columnar format, resulting in faster query times and improved performance. The method raw_sql_arrow() accepts raw SQL as input and processes it, producing output in a standard columnar format.
ds.sql_arrow("""SELECT round(coalesce(sum(m_6315f1de_RetailSales."m_revenue"), 0), 4)
AS "label_RetailSales.revenue",
datepart('year',
m_6315f1de_RetailSales.
"m_sales_date_1")
AS label_year FROM
m_6315f1de_RetailSales
GROUP BY label_year ORDER BY
label_year LIMIT 50002""")
Raw SQL Arrow Method#
SQL Dataframe#
The method sql_dataframe() takes a SQL query as input, where @ is used to refer to a column and # is used to refer to a table. It processes the query and returns the resulting data in a tabular format.
ds.sql_dataframe("""Select
@RetailSales.revenue,
@RetailSales.product,
@RetailSales.zip,
@RetailSales.delivery_date
from
#RetailSales""")
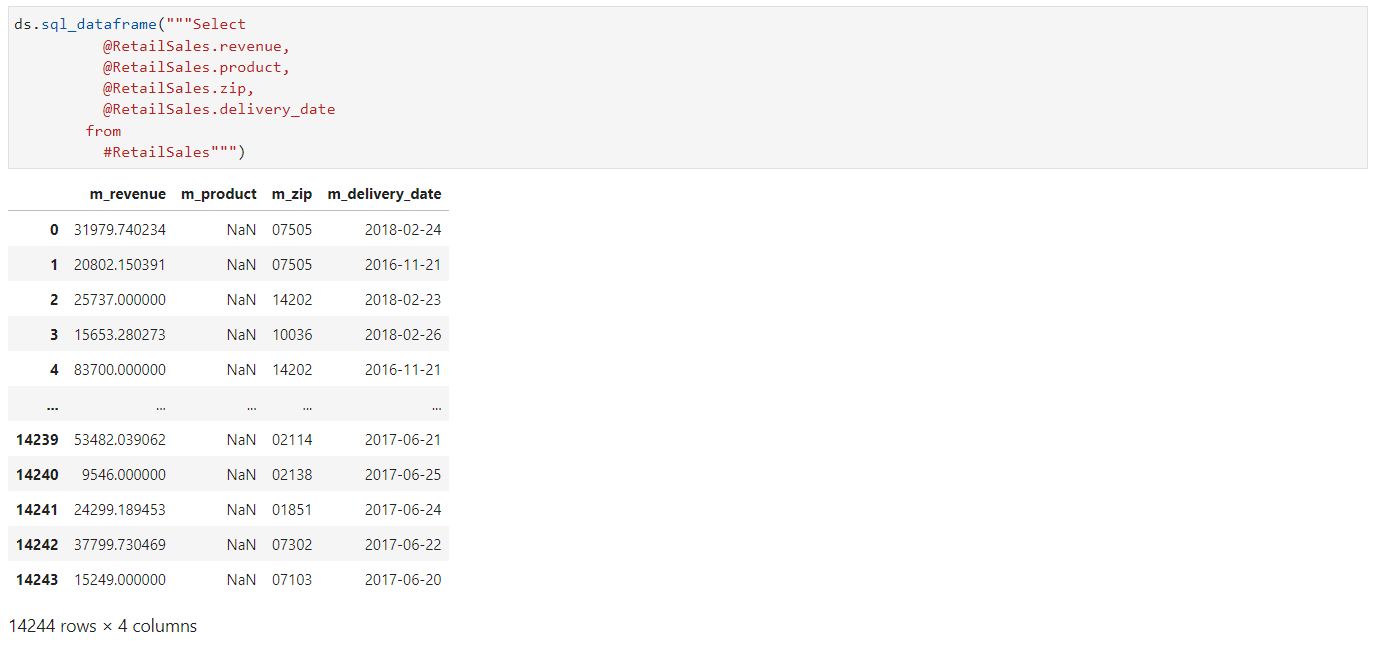
SQL Dataframe Method#
SQL Arrow#
The sql_arrow() method accepts a SQL query as input, with @ used to represent columns and # used to represent tables. It processes the query and returns the data in a standard columnar format, which is known for its efficiency and faster processing time compared to traditional SQL methods.
ds.sql_arrow("""Select
@RetailSales.revenue,
@RetailSales.product,
@RetailSales.zip,
@RetailSales.delivery_date
from
#RetailSales""")
SQL Arrow Method#
Pinboard Functionalities#
Let’s take a closer look at Pinboard Functionalities, which enable users to work with datasets. To start with csSDK Library in Jupyter Notebook, first import solution from csSDK Library.
from csSDK import Solution
# This will import Solution from the csSDK Library
Once an object is instantiated with the Solution() method, pressing the tab key reveals the list_templates() method, which can be used to retrieve a comprehensive list of available templates on the platform and their respective versions.
sn = Solution()
sn.list_templates()
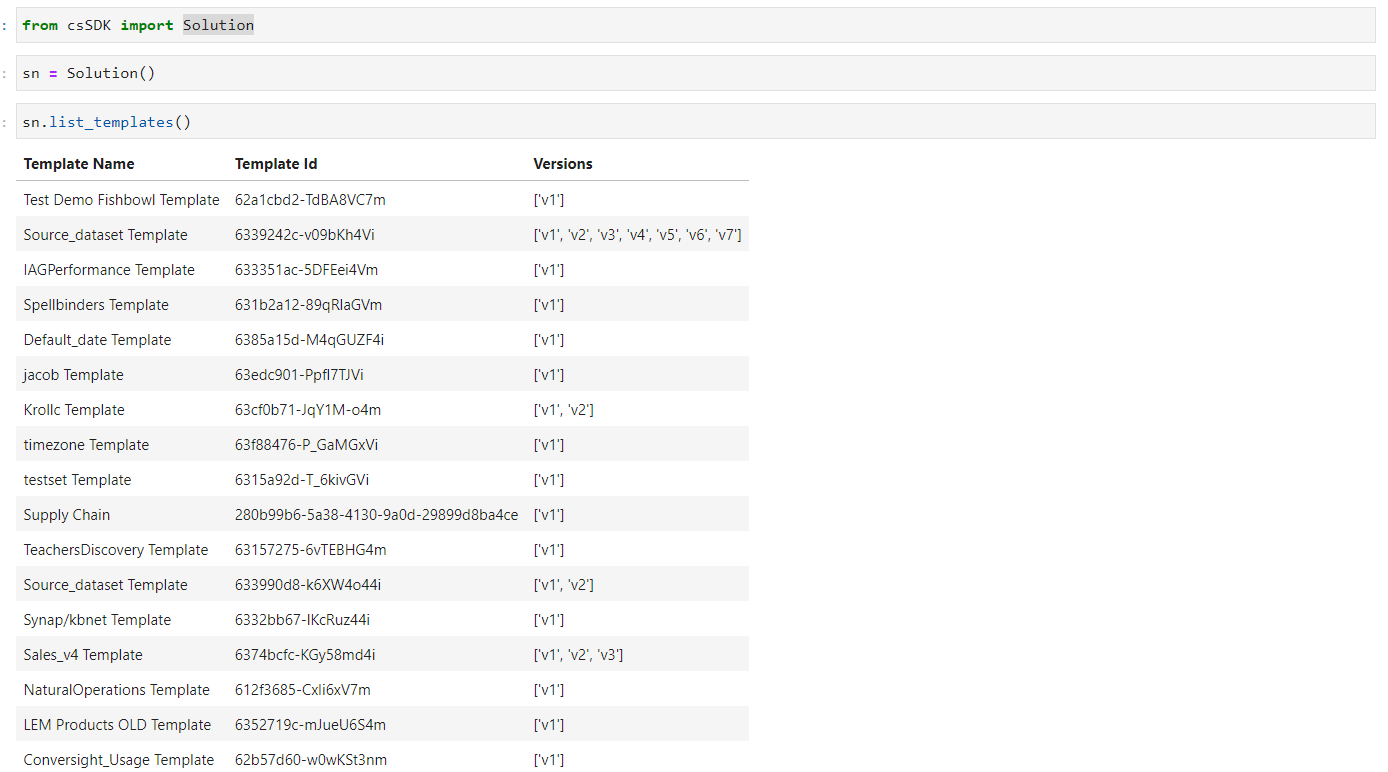
List of Available Templates#
To access Pinboard Functionalities, users can pass the template ID as a parameter to an object, which can then be utilized for Pinboard features.
sm=sn["280b99b6-5a38-4130-9a0d-29899d8ba4ce"]
Available Methods in Pinboard#
Pressing the Tab button on an object or function displays a list of the available methods. List of available methods for pinboard are shown in the below screenshot.

Pinboard Methods#
Get Versions#
The get_versions() method shows all available versions of a specified template, along with their corresponding templates.
sm.get_versions()

Get Version Method#
List of Pinboards#
When a version is passed as an argument, the list_pinboards() method displays the available pinboards.

Arguments for List of Pinboard#
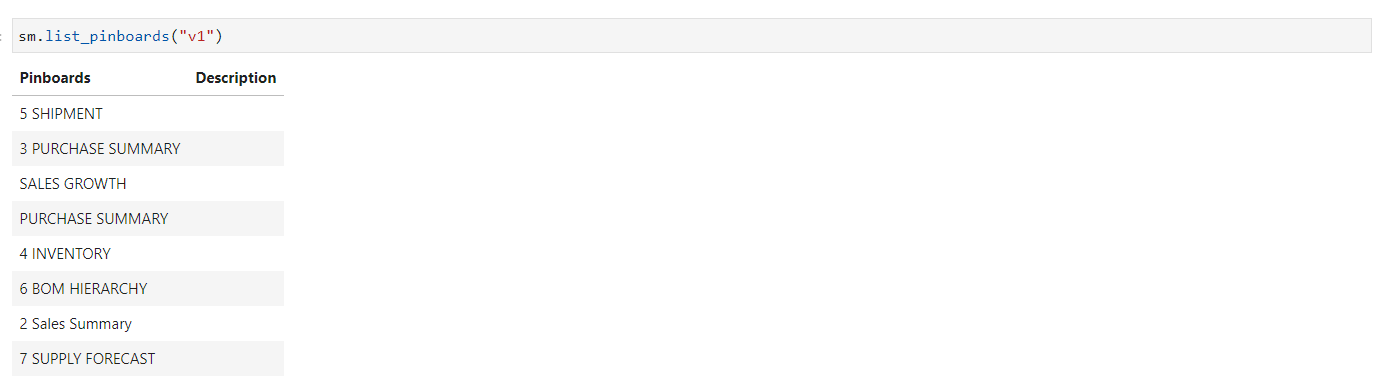
List of Pinboards#
Pinboards#
The Pinboard method only contains the create() function, which requires arguments for dataset ID and version. The create() function in the Pinboard method creates a pinboard within the specified dataset.
sm.pinboard.create()
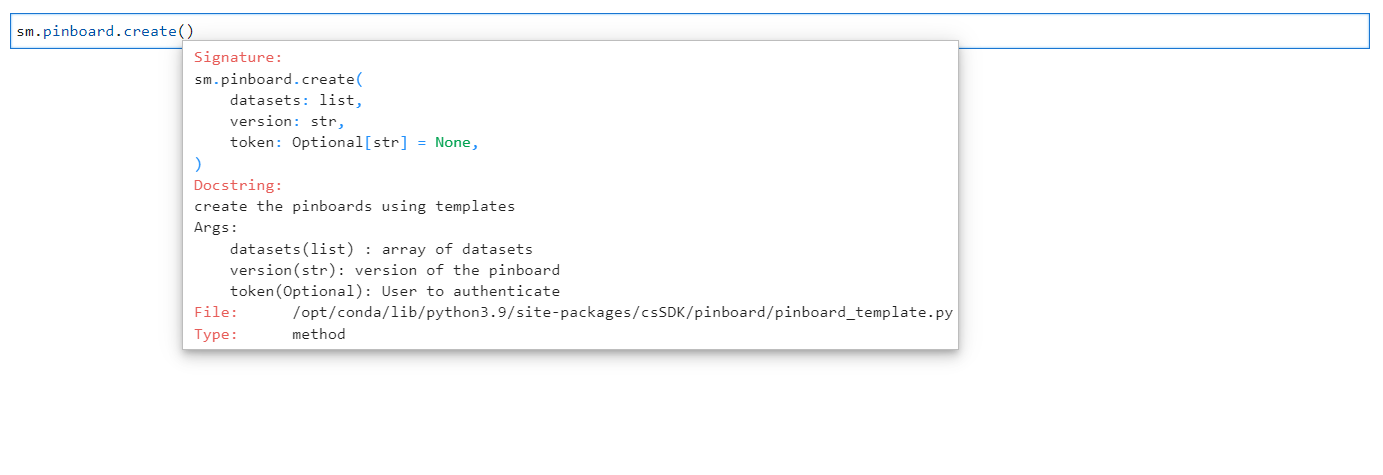
Arguments for Create Pinboard#

Pinboard Created#
After the pinboard is created, the assigned object displays a list of methods, which are listed below:
list_created_pinboards
share
unshare
delete
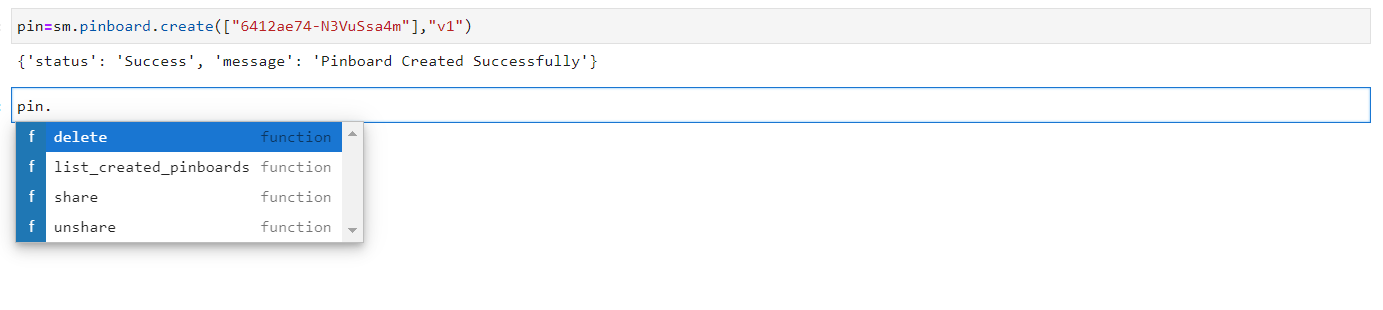
Pinboard Methods#
List of Created Pinboards: To display the ID and name of a pinboard that has been created, the method list_created_pinboards() can be utilized.
pin.list_created_pinboards()
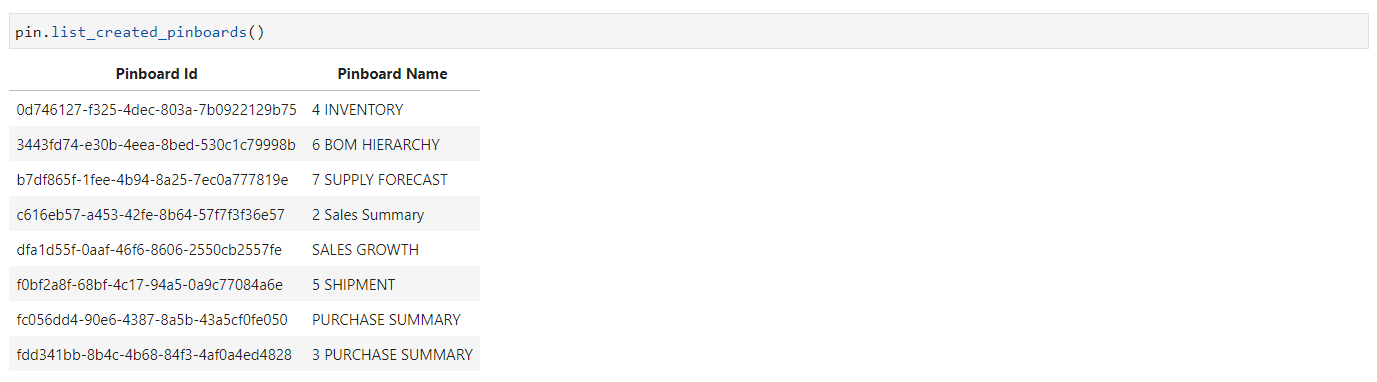
List of Created Pinboards#
Share: The method share() allows for the sharing of a pinboard with one or more users by including their email addresses. However, it is important to note that the recipient(s) must also have access to the dataset in order for the pinboard to be successfully shared.
The required arguments for the method “share()” are:
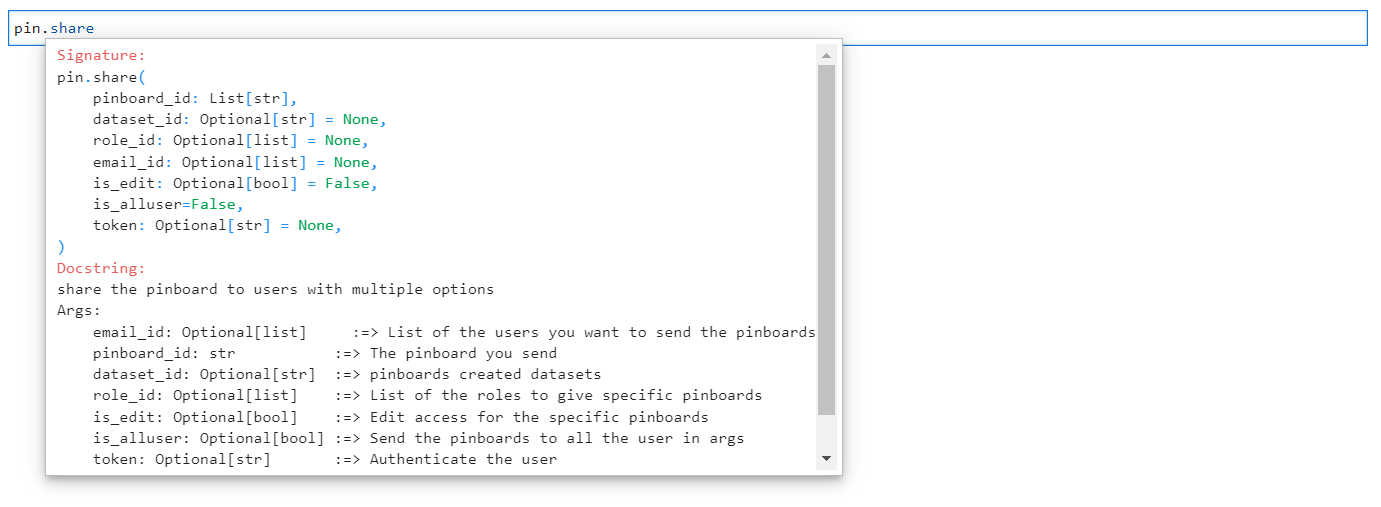
Arguments for Share method#
pin.share(email_id=["admin123@conversight.ai"],pinboard_id=["c616eb57-a453-42fe-8b64-57f7f3f36e57"])

Pinboard Shared#
Unshare: To remove a shared pinboard, the unshare() method requires the ID of the pinboard as well as the email address of the user with whom it was shared. The required arguments for the method “share()” are:
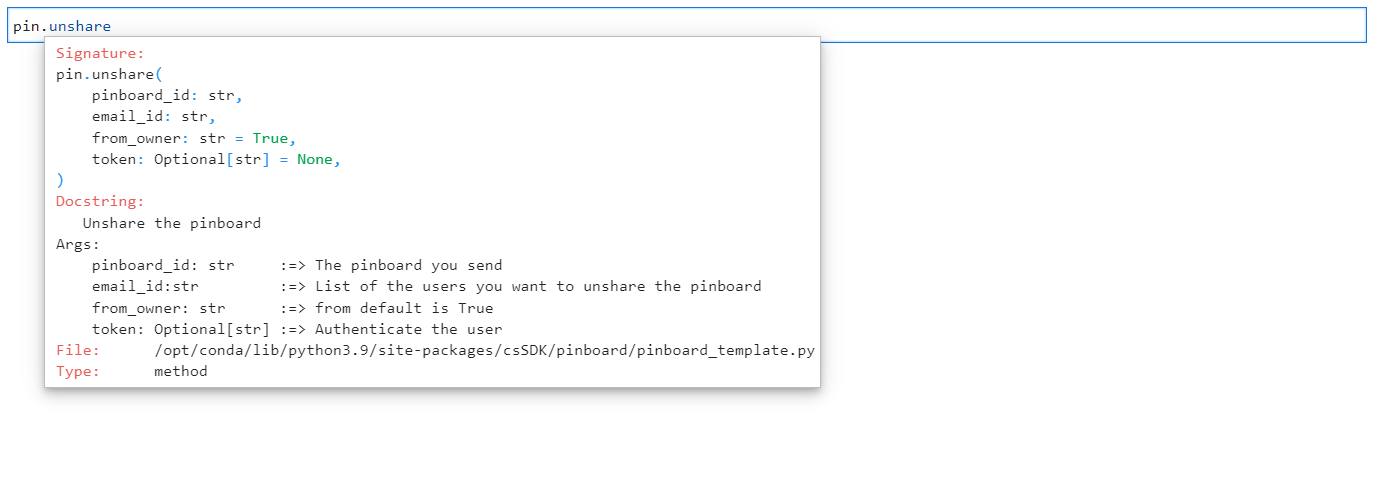
Arguments for Unshare method#
pin.unshare(email_id="admin123@conversight.ai",pinboard_id="c616eb57-a453-42fe-8b64-57f7f3f36e57")

Pinboard Unshared#
Delete: The delete() method is responsible for deleting a pinboard, along with any copies of the same pinboard that have been shared with other users. It takes pinboard ID as arguments.

Pinboard Deleted#
Using the csSDK, a range of actions can be executed including connecting datasets, viewing dataset details and metadata, retrieving group and role information, running queries and accessing pinned Storyboards. In the future, the csSDK will enable the creation, updating and deletion of Proactive Insights, Relationships, Drilldowns, smart analytics, smart column and smart query through Notebook.