Internal View#
Within the Internal View, users have the ability to access and customize the dataset available in the platform database. The category drop-down offers two options - Reference and Materialized - to refine your search.
Opting for Materialized loads the dataset into the knowledge graph and metadata, providing a comprehensive view of the data. On the other hand, selecting Reference creates a view of the data that is not loaded into the knowledge graph.
Furthermore, users have the option to select the Materialized View checkbox. By checking this box, the custom query is created as a new table in the database for others to utilize. If the checkbox is not selected, a reference table is created that will update automatically with changes to the original data. This option allows for greater flexibility and control when working with datasets.
Overall, these features provide users with the ability to customize and manipulate data to fit their specific needs, enhancing the utility of the platform for business operations.
Guidelines to work with an Internal View:#
Step 1: Enter a name for your smart query and select the category
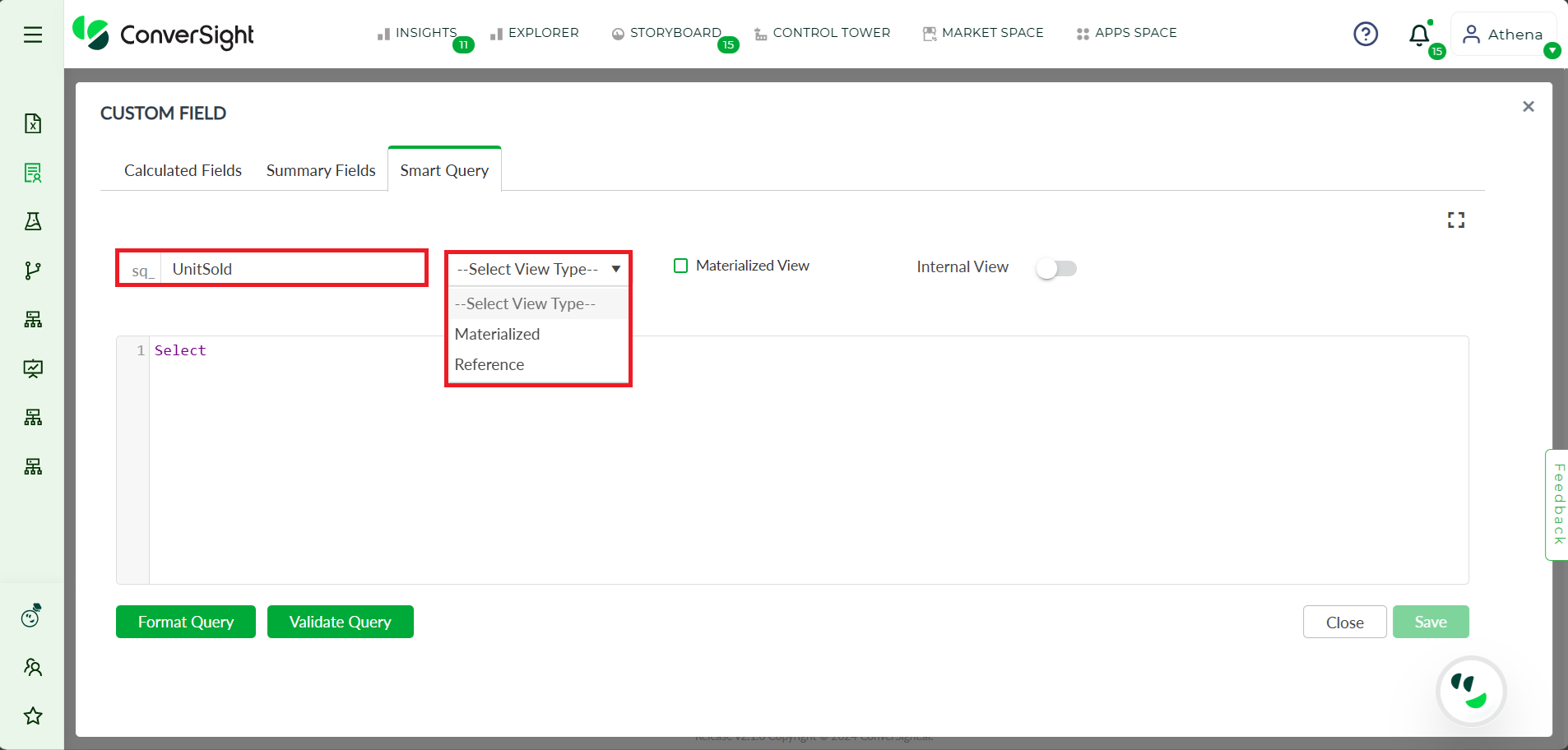
Smart Query#
Step 2: Enter the Smart Query in the query space.
For example, below is a sample query which retrieves a table. Enter @ lists out all the columns present in the database and # lists out all the tables in the database
SELECT
@Sheet1.customer AS "label_Sheet1.customer",
round(sum(coalesce(@Sheet1.available_qty, 0)), 0) AS "label_Sheet1.available_qty",
@Sheet1.order_date AS "label_Sheet1.order_date"
FROM
#Sheet1
GROUP BY
@Sheet1.customer,
@Sheet1.order_date
ORDER BY
"label_Sheet1.available_qty" DESC
Step 3: Click Format Query which formats the written query in SQL format and click Validate Query to ensure the query is accurate and error-free.
A sample table with 10 rows is displayed as result, click Save to save the Smart Query.
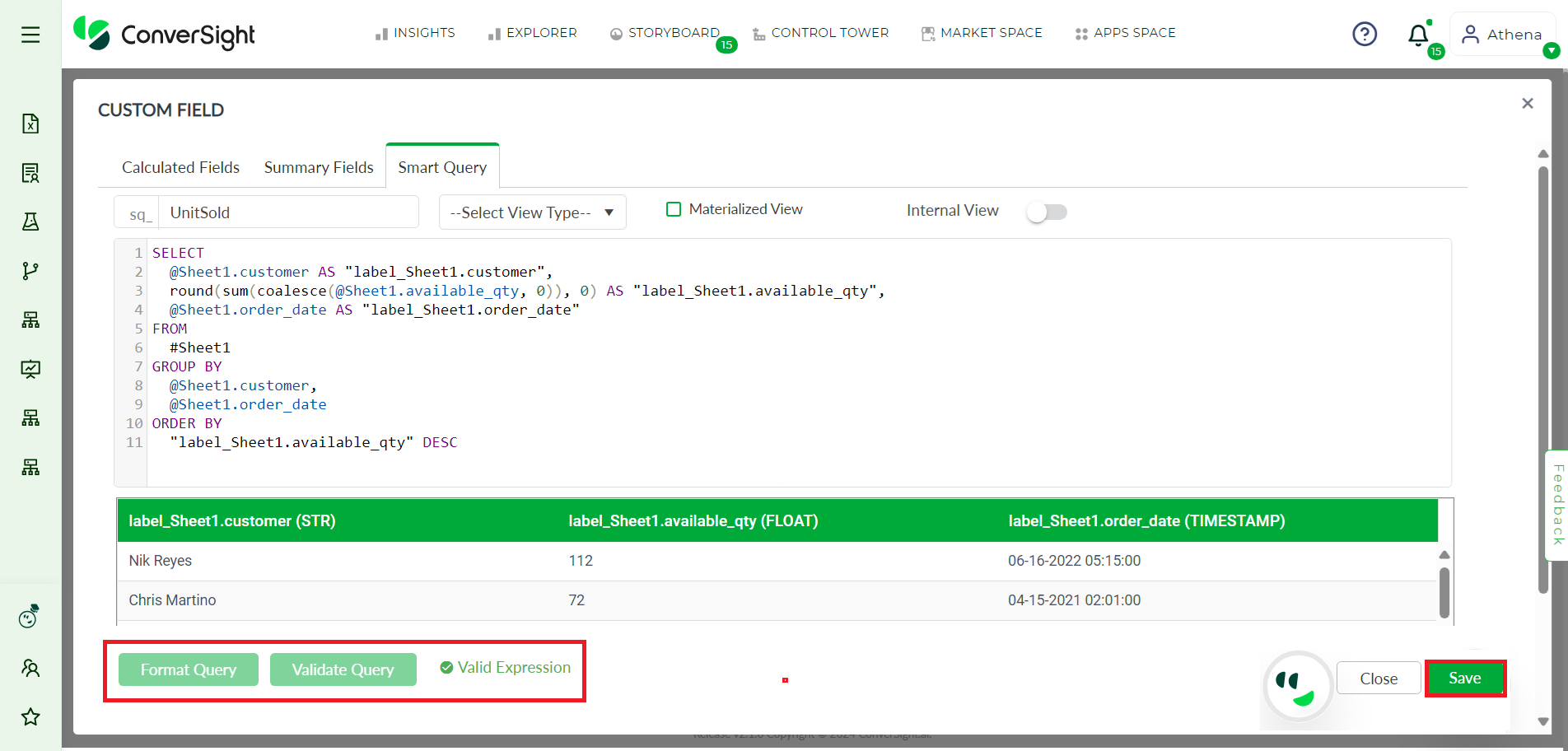
Validation and Save#
Step 4: The page will now redirect to SME coaching and your Smart Query is now ready to use.
Step 5: Click Publish to publish your Smart Query.
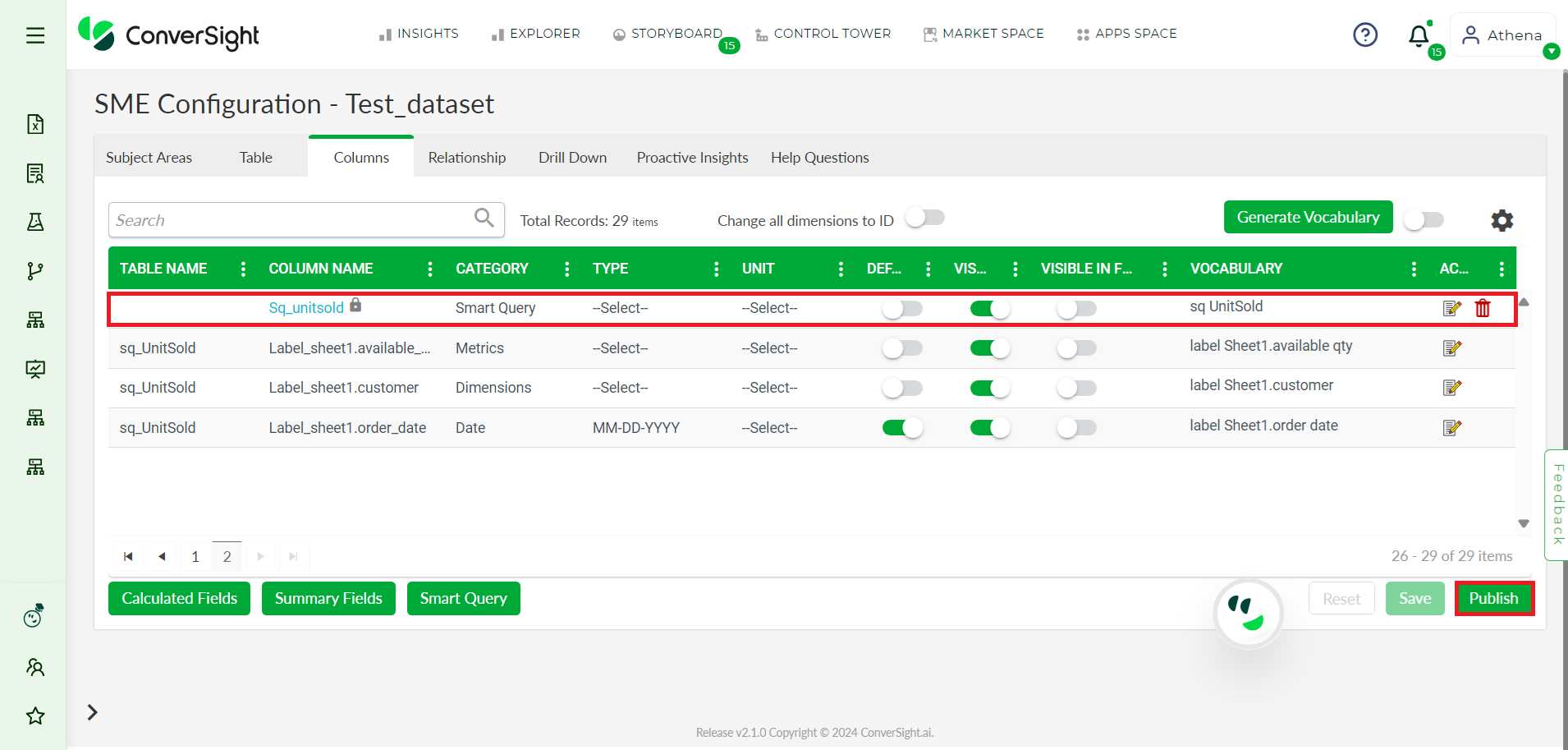
Smart Query#
The Smart Query table is safeguarded with a verification code that can only be accessed by the data administrator. While users can view the column names and data types, any modifications can only be made by the data administrator since the Smart Query is protected.
By adhering to these uncomplicated instructions, it is feasible for you to utilize a smart query in your enterprise and execute intricate analyzes on your data table with ease. Such actions can assist you in making knowledgeable choices and obtaining a competitive edge in your field.
Syntax for creating Smart Query#
The general syntax for creating a smart query in internal view is as follows:
SELECT
@TableName1.ColumnName1, @TableName2.ColumnName2, ... @TableNamen.ColumnName n
FROM
#TableName1, #TableName2, .... #TableNamen
WHERE Condition
Conditional filters empower users with a wide array of operators to effectively manipulate and interact with the SQL syntax presented above. This flexibility enables the precise extraction of data to meet specific requirements, making it a versatile tool for tailoring data retrieval according to your needs. We have
Comparison Operators#
Comparison operators in queries are used to evaluate and compare values. They enable you to perform actions like equality checks, range comparisons and null value validation.
Function |
Description |
|---|---|
= |
Equal to: Assesses equivalence of values in a specified column. |
<> or != |
Not equal to: Assesses non-equivalence of values in a specified column. |
> |
Greater than: Evaluates if the value on the left is greater than the right. |
>= |
Greater than or equal to: Determines if the value on the left is equal to or greater than the right. |
< |
Less than: Ascertain if the value on the left is smaller than the right. |
<= |
Less than or equal to: Assess whether the value on the left is less than or equal to the right. |
Is null |
Checks if a value in the specified column has no value or is missing. |
Is not null |
Verifies whether a value in the specified column is not null, indicating it has a value and is not missing. |
between |
Determines if a value falls within a specified range, inclusive of both lower and upper bounds in the specified column. |
not between |
Evaluates if a value does not fall within a specified range, excluding both lower and upper bounds in the specified column. |
Example syntax:
SELECT
@Employee.EmployeeID, @Employee.FirstName, @Employee.LastName, @Employee.Salary
FROM
#Employee
WHERE @Employee.Salary >= 60000.00
AND @Employee.LastName IS NOT NULL
Mathematical Functions#
Mathematical Functions enable the manipulation of numerical data in columns, providing features like absolute value, rounding, exponentiation, logarithms and others. These functions elevate the analytical capabilities by facilitating accurate mathematical computations on designated column values.
Function |
Description |
|---|---|
ABS(ColumnName) |
Calculates the absolute value of the column. |
CEIL(ColumnName) |
Rounds up the column values to the nearest integer. |
DEGREES(ColumnName) |
Converts an angle in radians to degrees in a column. |
EXP(ColumnName1,ColumnName2) |
Calculates the exponential value of the column. |
FLOOR(ColumnName) |
Calculates the largest integer less than or equal to numeric value of the column. |
LOG(ColumnName) |
Calculates the natural logarithm (base e) of numeric column. |
LOG10(ColumnName) |
Calculates the base-10 logarithm of numeric column. |
POWER(ColumnName1,ColumnName2) |
Calculates column1 values raised to the power of Column2. |
RADIANS(ColumnName) |
Converts an angle in degrees in the column to radians. |
ROUND(ColumnName) |
Rounds the column values to the nearest integer without changing the data type. |
ROUND_TO_DIGIT(ColumnName,decimal_places) |
Rounds the column values to a specific number of decimal places y. |
SIGN(ColumnName) |
Determines the sign of numeric column. |
SQRT(ColumnName) |
Returns the positive square root of the column. |
Statistical and Aggregate Functions#
Statistical and aggregate functions are mathematical computations to analyze data, offering valuable insights into data patterns and trends by summarizing information such as averages, totals and distributions.
NOTE
Statistical aggregate functions are applicable exclusively to metric columns.
Function |
Description |
|---|---|
AVG (ColumnName) |
Calculates the average value of data in the specified column |
COUNT (ColumnName) |
Provides the count of unique, non-repeated values within the specified column |
APPROX_MEDIAN (ColumnName) |
Returns the approximate median of the column |
MAX (ColumnName) |
Retrieves the maximum (largest) value in the specified column |
MIN (ColumnName) |
Retrieves the minimum (smallest) value in the specified column |
SUM (ColumnName) |
Calculates the sum of all numeric values in the specified column |
VARIENCE POP (ColumnName) |
Calculates population variance, indicating data spread |
STDDEV_POP (ColumnName) |
Calculates population standard deviation in the specified column |
STDDEV (ColumnName) or STDDEV_SAMP (ColumnName) |
Calculates sample standard deviation in a specified column |
COVAR_SAMP (ColumnName1, ColumnName2) |
Measures how two sets of data in a sample vary together |
Covar_pop (ColumnName1, ColumnName2) |
Calculates population covariance between two columns |
Example Syntax:
SELECT
AVG(@RetailSales.Revenue) AS AvgRevenue,
COUNT(@RetailSales.ProductID) AS UniqueProductCount,
MAX(@RetailSales.Revenue) AS MaxRevenue,
MIN(@RetailSales.Revenue) AS MinRevenue,
SUM(@RetailSales.Revenue) AS TotalRevenue,
VARIANCE_POP(@RetailSales.Revenue) AS VariancePopulation
FROM
#RetailSales
Date/Time Functions#
Date and time functions facilitate operations on date and time data, such as extracting parts, calculating intervals and manipulating timestamps, simplifying temporal data tasks.
Function |
Description |
|---|---|
CURRENT_DATE or CURRENT_DATE() |
Returns the current date in the GMT time zone. |
CURRENT_TIMEor CURRENT_TIME() |
Returns the current time of day in the GMT time zone. |
CURRENT_TIME or CURRENT_TIME() |
Returns the current timestamp in the GMT time zone. |
DATEADD(‘date_part’, interval, date | timestamp) |
Returns a date after a specified time/date interval has been added. |
DATEDIFF(‘date_part’, date, date) |
Returns the difference between two dates, calculated to the lowest level of the date_part you specify. For example, if you set the date_part as MONTH, only the year and month are used to calculate the result. Other fields, such as day, hour and minute are ignored. |
DATEPART(‘date_part’, date) |
Datepart function is used to extract a specific part or component from a date or timestamp. |
DATE_TRUNC(date_part, timestamp) |
Rounds down a date or time to a specific part like month, day or hour. |
EXTRACT(date_part FROM timestamp) |
Extracts specific parts (e.g., year, month, day) from a full date or timestamp. |
INTERVAL ‘count’ date_part |
Adds or Subtracts count date_part units from a timestamp. Note that ‘count’ is enclosed in single quotes and it can be either Timestamp or date column. |
NOW() |
Return the current timestamp in the GMT time zone. Same as CURRENT_TIMESTAMP(). |
TIMESTAMPADD(date_part, count, timestamp | date) |
Adds a specific date_part count to a timestamp or date. |
TIMESTAMPDIFF(date_part, timestamp1, timestamp2) |
It is used to calculate the difference between two timestamps based on a specified date part. |
Dynamic Filters#
Dynamic filters adjust the time range of data retrieval based on the current date, allowing for flexible and contextually relevant queries. For instance, a dynamic filter set to last 6 months adapts to the current execution date, retrieving data from the six months preceding that date. This ensures that the query provides timely and accurate information, making it adaptable to varying timeframes depending on when the query is executed.
Supported Dynamic Filters: [last week, this week, next week, last month, this month, next month, last quarter, this quarter, next quarter, last calendar year, last financial year, this calendar year, last 3 months, last 6 months, last 12 months, next 30 days, next 60 days, next 90 days, next 180 days, next 360 days, next 3 months, next 6 months, next 12 months.]
For example:
SELECT
*
FROM
#RetailSales
WHERE
CAST(@RetailSales.delivery_datenew AS DATE) BETWEEN (* last 6 month *)
Supported date part types:#
DATEDIFF [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, week]
DATE_TRUNC [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, millennium, century, decade, week,quarterday]
EXTRACT [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, dow, isodow, doy, epoch, quarterday, week, week_sunday, dateepoch]
Supported interval types:#
DATEADD [decade, year, quarter, month, week, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
DATEPART [year, quarter, month, dayofyear, quarterday, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
TIMESTAMPDIFF [year, quarter, month, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
Accepted Date, Time and Timestamp Formats:
Data Types |
Format |
Example |
|---|---|---|
Date |
MM:DD:YYYY |
03:28:2023 |
Date |
DD:MM:YYYY |
30:03:2023 |
Date |
YYYY:MM:DD |
2023:31:10 |
Date |
YYYY:DD:MM |
2023:31:03 |
Time |
HH:MM:SS |
12:32:24 |
Time Stamp |
Date Time |
20-OCT-23 16:58:32 |
String Functions#
String functions enable efficient manipulation of text data, including tasks like concatenation, searching and formatting.
Function |
Description |
|---|---|
BASE64_ENCODE(str) |
Encodes a string to a BASE64-encoded string. |
BASE64_DECODE(str) |
Decodes a BASE64-encoded string. |
CHAR_LENGTH(str) |
Char_length function returns the number of characters in a string. |
str1||str2 |
Returns the string obtained by concatenating the specified strings. It’s important to note that numeric, date, timestamp and time types will be automatically converted to strings as needed. Therefore, explicit casting of non-string types to string types is unnecessary when using the concatenation operator with these inputs. |
INITCAP(str) |
Produces a string in which the first letter, as well as any subsequent letters following defined delimiter characters, are in uppercase, while the remaining characters are in lowercase. Accepted delimiter characters include !, ?, @, “, ^, #, $, &, ~, _, ,, ., :, ;, +, -, *, %, /, |, , [, ], (, ), {, }, <, >. |
KEY_FOR_STRING(str) |
Key_for_string function returns the dictionary key of a dictionary-encoded string column. |
LCASE(str) |
Returns the string in lowercase, with current support limited to the ASCII character set. Equivalent to the LOWER function. |
LENGTH (str) |
Length function returns the length of a string in bytes. |
LOWER(str) |
Returns the string in lowercase, with current support limited to the ASCII character set. Equivalent to the LCASE function. |
LEFT(str, num) |
Provides the leftmost specified number (num) of characters from the string (str). |
LPAD(str, len, lpad_str ) |
Left-pads the string (str) with the specified padding string (lpad_str) to achieve a total length of len. If lpad_str is not provided, the space character is used for padding. If the length of str exceeds len, characters from the end of str are truncated to match the length of len. The padding process involves adding characters from lpad_str sequentially until the desired length len is reached. If the concatenation of lpad_str and str is insufficient to meet the target len, lpad_str is repeated, potentially in partial segments, until the desired length is achieved. |
LTRIM(str, chars) |
Removes leading characters defined in chars from the string. Functions identically to the TRIM operation. |
OVERLAY(str PLACING replacement_str FROM start FOR len) |
In the given string (str), this operation substitutes a specified number of characters (len) starting from the specified position (start) with the characters defined in replacement_str. The replacement involves removing len characters from str and inserting the replacement_str, unless the combined length of start and replacement_str exceeds the length of str. In such cases, all characters from the start position to the end of str are replaced. If the start value is negative, it indicates the number of characters counted from the end of str. |
POSITION( search_str IN str FROM start_position) |
Provides the position of the initial character in the search_str within the str, with the option to commence the search from start_position. Returns 0 if search_str is not located. Returns null if either search_str or str is null. |
REPEAT(str, num) |
Duplicates the string based on the specified repetition count(num). |
REPLACE(str, existing_substr, new_str) |
Updates the string by replacing every instance of the substring from_str with the new substring new_str. |
REVERSE(str) |
Reverses the given string. |
RIGHT(str, num) |
Provides the rightmost specified number (num) of characters from the string (str). |
RPAD(str, len, rpad_str) |
Pads the string on the right with the specified string (rpad_str) to achieve a total length of len. If rpad_str is not provided, space characters are used for padding. If the length of str exceeds len, characters from the start of str are truncated to match the length of len. The padding involves adding characters from rpad_str sequentially until the desired length len is reached. If the concatenation of rpad_str and str is insufficient to meet the target len, rpad_str is repeated, potentially in partial segments, until the desired length is achieved. |
RTRIM(str) |
Removes any trailing spaces from the string. |
SPLIT_PART(str, ‘delim’, field_num) |
Divide the string using a specified delimiter (delim) and retrieve the field identified by the field number (field_num). Fields are numbered sequentially from left to right. |
STRTOK_TO_ARRAY(str, ‘delim’ ) |
Splits the string, str, into tokens using optional delimiter(s), delim and provides an array of these tokens. If no tokens are generated during the process, an empty array is returned. If either parameter is NULL, the result is also NULL. |
SUBSTR(str, start, len) or SUBSTRING(str FROM start FOR len) |
Returns a substring of the string (str) starting at the index specified by start and extending for len characters. The indexing is 1-based, meaning the first character of str is at index 1 (not 0). However, start 0 is equivalent to start 1. If start is negative, it denotes |
TRIM( BOTH | LEADING | TRAILING trim_str FROM str) |
Removes characters defined in trim_str from the beginning, end or both of str. If trim_str is not specified, the space character is the default. If the trim location is not specified, defined characters are trimmed from both the beginning and end of str. |
TRY_CAST( str AS type) |
The TRY_CAST function tries to change a string into a numeric, timestamp, date or time format. If it succeeds, you get the converted value; if it fails (for example, if the string isn’t in a valid format for the chosen type), you get null. Just remember, TRY_CAST only works for converting strings. |
UCASE(str) |
Provides the string in uppercase format, with current support limited to the ASCII character set. Equivalent to the UPPER function. |
UPPER(str) |
Returns the string in uppercase, with current support limited to the ASCII character set. Equivalent to the UCASE function. |
For example:
SELECT
BASE64_ENCODE(@TableName.ColumnName1) AS encoded_value,
INITCAP(@TableName.ColumnName2) AS init_cap_value,
LEFT(@TableName.ColumnName3, 3) AS leftmost_chars,
LPAD(@TableName.ColumnName4, 10, ' ') AS left_padded_value,
OVERLAY(@TableName.ColumnName5 PLACING 'hello' FROM 1 FOR 3) AS overlay_result,
POSITION('String' IN @TableName.columnName6 FROM 1) AS position_result,
REPEAT(@TableName.columnName7, 2) AS repeated_value,
REPLACE(@TableName.columnName8, 'hello', 'world') AS replaced_value,
RIGHT(@TableName.columnName9, 4) AS rightmost_chars,
SPLIT_PART(@TableName.columnName10, '-', 2) AS split_part_result,
SUBSTRING(@TableName.columnName11 FROM 2 FOR 5) AS substring_result,
FROM
#tableName;
Pattern Matching Functions#
Pattern matching functions are functions in SQL that allow you to search for specific patterns or substrings within text or character data. These functions are commonly used to query, filter or manipulate data based on matching patterns in strings.
Function |
Description |
Syntax |
|---|---|---|
LIKE ‘PATTERN’ |
Returns true if the string matches the pattern. |
CASE WHEN @TableName.ColumnName LIKE ‘%Pattern%’ THEN result1 ELSE result2 END |
NOT LIKE ‘PATTERN’ |
Returns true if the string does not match the pattern. |
CASE WHEN @TableName.ColumnName NOT LIKE ‘%Pattern%’ THEN result1 ELSE result2 END |
ILIKE ‘PATTERN’ |
Used for case-insensitive pattern matching, ignoring letter case. |
CASE WHEN @TableName.ColumnName ILIKE ‘%Pattern%’ THEN result1 ELSE result2 END |
REGEXP ‘POSIX_PATTERN’ |
Used for complex text pattern matching with POSIX regular expressions. |
CASE WHEN @TableName.ColumnName REGEXP ‘posix_pattern’ THEN result1 ELSE result2 END |
REGEXP_LIKE (TableName.ColumnName) |
Checks if a string matches a specified POSIX regular expression pattern. |
CASE WHEN REGEXP_LIKE(@TableName.ColumnName, ‘Posix_pattern’) THEN result1 ELSE result2 END |
Example Syntax:
SELECT
CASE
WHEN @TableName.ColumnName1 LIKE 'abc' THEN result1
ELSE result2
END AS result_for_like_pattern,
CASE
WHEN @TableName.ColumnName2 ILIKE 'abc' THEN result1
ELSE result2
END AS result_for_ilike_pattern,
CASE
WHEN @TableName.ColumnName3 regexp 'Miss' THEN result1
ELSE result2
END AS result_for_regexp_posix_pattern,
CASE
WHEN regexp_like(TableName.@ColumnName4, 'ness') THEN result1
ELSE result2
END AS result_for_regexp_like_pattern
FROM #TableName
Window Functions#
Window functions, also known as windowing or analytic functions, are a category of functions that perform a calculation across a specified range of rows related to the current row within a query result set. Unlike aggregate functions that work on an entire result set, window functions operate on a window of rows that are somehow related to the current row.
Function |
Description |
Syntax |
|---|---|---|
LEAD(ColumnName,Offset) |
Retrieves the value of a column from a subsequent row within the window frame. |
SELECT @TableName.ColumnName, LEAD(@TableName.ColumnName, offset) Over (ORDER BY @TableName.ColumnName) FROM #Tablename |
LAG(ColumnName,offset) |
Retrieves the value of a column from a previous row within the window frame. |
SELECT @TableName.ColumnName, LAG(@TableName.ColumnName, offset) OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
RANK() |
Assigns a unique rank to each distinct row within the window frame. |
SELECT @TableName.ColumnName, RANK() OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
ROW_NUMBER() |
Assigns a unique number to each row within the window frame. |
SELECT @TableName.ColumnName, ROW_NUMBER() OVER (ORDER BY @TableName.ColumnName) FROM #Tablename |
DENSE RANK() |
Assigns a dense rank to each distinct row within the window frame. |
SELECT @TableName.ColumnName, DENSE_RANK() OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
FIRST_VALUE(ColumnName) |
Retrieves the first value within the window frame. |
SELECT @TableName.ColumnName, FIRST_VALUE(@TableName.ColumnName) OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
LAST_VALUE(ColumnName) |
Retrieves the last value within the window frame. |
SELECT @TableName.ColumnName, LAST_VALUE(@TableName.ColumnName) OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
NTILE(number_of_groups) |
Divides the result set into a specified number of roughly equal groups, assigning a group number to each row. |
SELECT @TableName.ColumnName, NTILE(Number_of_groups) OVER (ORDER BY @TableName.ColumnName) FROM #tablename |
PERCENT_RANK |
Calculates the relative rank of a value within the window frame as a percentage. |
SELECT @TableName.ColumnName, PERCENT_RANK() OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
CUME_DIST |
Calculates the cumulative distribution of a value within the window frame. |
SELECT @TableName.ColumnName, CUME_DIST() OVER (ORDER BY @TableName.ColumnName) FROM #TableName |
Frame Aggregated Functions#
Various aggregate functions such as SUM(), COUNT(), AVERAGE(), MAX(), MIN() applied over a particular frames are called aggregate frame functions.
SELECT
@TableName.Column1,@TableName.Column2,@TableName.Column3,@TableName.ColumnN, Frame_Aggregated_Function(@TableName.Column)
OVER( PARTITION BY @TableName.Partition_column)
FROM #TableName
Function |
Description |
Syntax |
|---|---|---|
MIN(ColumnName) |
Returns the smallest value within the specified window frame. |
SELECT @Column, MIN(@Column) OVER (PARTITION BY @Partition_column) FROM #tablename |
MAX(ColumnName) |
Returns the largest value within the specified window frame. |
SELECT @Column, MAX(@Column) OVER (PARTITION BY @Partition_column) FROM #tablename |
Sum(ColumnName) |
Calculates the sum of values within the specified window frame. |
SELECT @Column, SUM(@Column) OVER (PARTITION BY @Partition_column) FROM #tablename |
AVG(ColumnName) |
Computes the average of values within the specified window frame. |
SELECT @Column, AVG(@Column) OVER (PARTITION BY @Partition_column) FROM #tablename |
COUNT(ColumnName) |
Counts the number of rows within the specified window frame. |
SELECT @Column, COUNT(@Column) OVER (PARTITION BY @Partition_column) FROM #tablename |